
これまでの常識は間違っていた?!Lambdaのコールドスタート対策にはメモリ割り当てを減らすという選択肢が有効に働く場面も
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
先日のBlack BeltでLambdaの内部構造について一部解説がありました。※スライド公開され次第更新します
これまでWorkerというコンポーネントはMicroVMを指しているという理解だったのですが、実際にはMicroVMをホストするEC2インスタンスのレイヤーがWorkerに相当するようです。以後の「Worker」という表記は基本的に「MicroVM」に置き換えて読んで頂くようお願いします。

はじめに
サーバーレス開発部@大阪の岩田です。
既に多くの方がご存知だと思いますが、Lambdaにはコールドスタートという概念が存在します。一般的にはLambda関数実行時にLambda実行環境の初期化処理が伴う場合を「コールドスタート」と呼ぶことが多いですが、このLambda実行環境の初期化処理には大きく2つのパターンが存在するようです。※厳密に区別すればもっと多くのパターンに別れるはずですが、ここでは2つとします。
本エントリでは、この2つのパターンの違いについて紹介するとともに、Lambdaというサービスの裏側について考察してみます。 以後記載している内容はあくまでも私の主観に基づく考察です。実際の仕様とは異なる可能性があることをあらかじめご了承ください。
コールドスタートとは?!
まずはコールドスタートの定義にについておさらいです。先日のBlackBeltの発表資料ではコールドスタートについて以下のように説明されています。
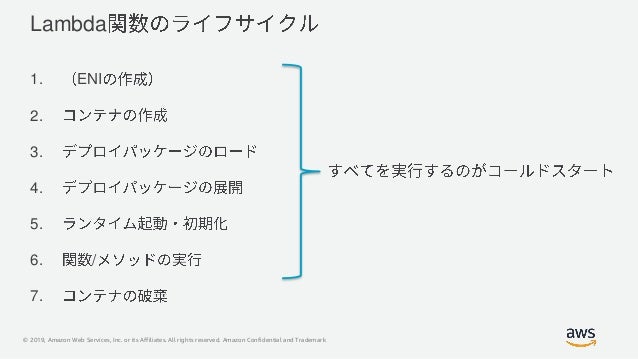
詳細はSlideShareの資料をご参照ください。
今回紹介したいのが、上記資料の1〜6を実行するパターン以外に2〜6のみを実行するパターンが存在するということです。以後順を追って説明します。
なお、以降の記述においては用語の意味を以下のように定義させて頂きます。
- コールドスタート
- Lambdaランタイムの初期化処理を伴う実行パターン
- 上記Black Beltの資料における定義とは異なりますが、Lambda関数のhandler外のコードが実行されるような実行パターンは全てコールドスタートと定義します。
- 狭義のコールドスタート
- 後述するWorkerのプロビジョニングを伴う(と予想される)実行パターン
- 上記Black Beltの資料でのコールドスタートの定義と同等の定義 VPC LambdaにおいてはENIの作成&アタッチを伴います。
VPC Lambdaの挙動を分析する
コールドスタートの挙動を理解するために、いくつかのパターンでLambdaを実行しつつX-Rayから取得した情報を分析してみます。
検証1.VPC Lambda × メモリ128Mの場合
まず以下のスクリプトを使ってVPC Lambdaのコールドスタート所要時間を計測してみました。メモリを128M割り当てたVPC Lambdaを作成&実行し、Lambda実行にかかった所用時間をX-Rayから取得します。
import boto3
from datetime import datetime, timedelta, timezone
import time
def filter_trace(x, fnc_name):
resource_arns = x['ResourceARNs']
filterd_resource = [i for i in resource_arns if i['ARN'].startswith(f'arn:aws:lambda:ap-northeast-1:<AWSアカウントID>:function:{fnc_name}_')]
return len(filterd_resource) != 0
def main():
xray = boto3.client('xray')
lambda_client = boto3.client('lambda')
for i in range(1, 11):
fnc_name = f'vpc_lambda_{i}'
t1 = time.time()
lambda_client.create_function(
FunctionName=fnc_name, Runtime='nodejs8.10',Handler='hello.handler',
Role='適当なLambda実行ロールのARN',
Code={'ZipFile':open('hello.zip','rb').read()},
TracingConfig={'Mode': 'Active'},
MemorySize=128,
VpcConfig={
'SubnetIds': ['<適当なサブネットID>'],
'SecurityGroupIds': ['<適当なセキュリティグループのID>']
}
)
lambda_client.invoke(FunctionName=fnc_name)
# Workerが再利用されないようにLambdaの実行が全て完了してから削除
for i in range(1, 11):
fnc_name = f'vpc_lambda_{i}'
lambda_client.delete_function(FunctionName=fnc_name)
# X-Rayに反映されるまでちょっと待つ
time.sleep(30)
JST = timezone(timedelta(hours=+9), 'JST')
end_time = datetime.now(JST)
start_time = end_time - timedelta(minutes=5)
res = xray.get_trace_summaries(StartTime=start_time, EndTime=end_time)
summaries = res['TraceSummaries']
traces = filter(lambda x :filter_trace(x, 'vpc_lambda'), summaries)
for trace in traces:
print(int(trace['Duration'] * 1000))
if __name__ == '__main__':
main()
指定しているhello.zipの中身は以下のコードをZIP化したものです。
exports.handler = async (event) => {
const response = {
statusCode: 200,
body: JSON.stringify('Hello from Lambda!'),
};
return response;
};
結果は以下のようになりました。
| NO | 所要時間(ミリ秒) |
|---|---|
| 1 | 273 |
| 2 | 220 |
| 3 | 234 |
| 4 | 254 |
| 5 | 194 |
| 6 | 250 |
| 7 | 204 |
| 8 | 10,019 |
| 9 | 268 |
| 10 | 251 |
| 平均 | 1,217 |
| 中央値 | 251 |
| 最大 | 10,019 |
| 最小 | 194 |
| 分散 | 9,566,172 |
ん・・・??VPC Lambdaは遅い遅いと聞いていましたが、ほとんどのケースにおいて1秒未満で実行が完了しています。なぜ??
X-Rayのトレース結果を確認しても、Initialization処理が実行されています。

VPC Lambdaに関するドキュメントを再確認したところ、それらしき記述を見つけました。
Lambda 関数で VPC にアクセスする場合は、Lambda 関数でのスケーリング要件をサポートできる充分な ENI キャパシティーが VPC にあることを確認します。次の式を使用すると、ENI 要件を概算できます
Projected peak concurrent executions * (Memory in GB / 3GB)次のとおりです。
- Projected peak concurrent execution (投射されたピーク時の同時実行) – この値を決定するには、「同時実行数の管理」の情報を使用します。
- メモリ – Lambda 関数用に設定したメモリの容量。
VPC 対応の Lambda 関数をセットアップするためのガイドライン
先ほどの計測ではメモリを128M割り当てたLambda関数を10個作成しているので、上記の式で計算すると消費されるENIは1つに収まりそうです。つまり、ENIの作成処理が1度しか行われなかったため、残り9回の処理に関しては秒単位の大きなオーバーヘッドが発生しなかったのです。
ENIの状況を確認する
実際にENIがどうなっているか確認してみます。

Lambda関数自体は10個作成しましたが、Lambdaに紐づくENIは1つしか存在しません。やはり先ほどの公式に従ってENIが作成されており、1つのENIを複数のLambda実行環境で共有しているようです。
検証2.VPC Lambda × メモリ3008Mの場合
前述の公式に従うと、1つのENIを共有できるLambda実行環境の総メモリサイズは3Gのようです。よってLambda関数に割り当てるメモリサイズを最大の3008Mに設定すると1つのLambda実行環境が1つのENIを占有することになりそうです。先ほどのコードのMemorySize=128の部分をMemorySize=3008に書き換えて再度実行してみましょう。
結果は以下のようになりました。
| NO | 所要時間(ミリ秒) |
|---|---|
| 1 | 9,475 |
| 2 | 13,851 |
| 3 | 9,478 |
| 4 | 9,419 |
| 5 | 9,539 |
| 6 | 10,917 |
| 7 | 7,922 |
| 8 | 10,890 |
| 9 | 14,897 |
| 10 | 10,062 |
| 平均 | 10,645 |
| 中央値 | 9,801 |
| 最大 | 14,897 |
| 最小 | 7,922 |
| 分散 | 4,633,741 |
ENIの状況を確認する
先ほどと同様にENIがどうなっているか確認してみます。

今度はENIが10個作成されています。これなら遅いのも納得ですね。
考察
これまでの調査結果を踏まえて考察していきます。
以後記載している内容はあくまでも私の主観に基づく考察です。実際の仕様とは異なる可能性があることをあらかじめご了承ください。
これまでの調査結果を踏まえるとENIとLambdaの実行環境は1:Nの関係性を持つようです。ここで、改めてLambdaのバックエンドがどのように稼働している復習します。Lambdaのバックエンドの仕組みについてはre:Invent 2018のセッションにて言及されています。
セッションの内容をまとめたこちらのブログもご参照ください。
こちらのセッションによると、Lambdaにはサンドボックス環境とWorkerというコンポーネントが存在します。サンドボックス環境はLambda関数を実行するためのコンテナに相当し、Workerはサンドボックス環境をプロビジョニングするための仮想OSのレイヤに相当します。VPC Lambdaを実行するために作成されたENIはWorkerにアタッチされるとのことなので、イメージ的にはこんなイメージでしょうか?

Lambda関数のメモリ割り当てが少ない場合はこんな感じでWorker内に多数のサンドボックス環境がプロビジョニングされるていることでしょう。

この状態で新たにLambda関数の作成&実行要求があった場合、現在利用中のWorker内にサンドボックス環境が構築されて、Lambda関数が実行されると考えられます。

逆にLambda関数のメモリ割り当てが大きい場合はこんな感じで1つのサンドボックス環境が1つのWorkerを占有していることでしょう。

この状態で新しくLambda関数の作成&実行要求があった場合、利用中のWorker上にははこれ以上サンドボックス環境を構築するメモリのキャパシティが残っていないので、WorkerManagerが新たにWorkerの割り当てを行い、VPC Lambdaの場合はさらにENIの作成&アタッチ処理が実行されると考えられます。 Workerに3G以上の大量のメモリを割り当てつつ1つのWorkerに複数のENIをアタッチして使い回す構成も考えられますが、WorkerはAWSアカウント間で分離されていることを考えると、Workerがビジー状態を保つように大量のメモリ割り当ては行わないと予想します。

非VPC Lambdaの挙動を分析する。
サンドボックス環境をプロビジョニング可能なWorkerが対象AWSアカウントに割り当て済みでない場合に狭義のコールドスタートが発生すると考えると、ENIの作成を伴わない非VPCLambdaにおいてもLambda関数に割り当てるメモリサイズを小さくすることで新しいWorkerを割り当てるオーバーヘッドを減らせそうです。実際に計測してみます。
検証3.非VPC Lambda × メモリ128Mの場合
検証1.のコードからVpcConfig=...の部分を削除して実行。非VPC Lambdaのコールドスタート所要時間を計測します。以下のような結果になりました。
| NO | 所要時間(ミリ秒) |
|---|---|
| 1 | 247 |
| 2 | 319 |
| 3 | 219 |
| 4 | 318 |
| 5 | 241 |
| 6 | 226 |
| 7 | 241 |
| 8 | 202 |
| 9 | 228 |
| 10 | 238 |
| 平均 | 248 |
| 中央値 | 240 |
| 最大 | 319 |
| 最小 | 202 |
| 分散 | 1,553 |
検証4.非VPC Lambda × メモリ3008Mの場合
検証3のコードのMemorySize=128の部分をMemorySize=3008に書き換えて再度実行してみましょう。考察が正しければ毎回追加のWorker割り当てが実行されて、検証3より遅くなるのでは・・・?
| NO | 所要時間(ミリ秒) |
|---|---|
| 1 | 182 |
| 2 | 169 |
| 3 | 190 |
| 4 | 204 |
| 5 | 175 |
| 6 | 181 |
| 7 | 184 |
| 8 | 191 |
| 9 | 194 |
| 10 | 170 |
| 平均 | 184 |
| 中央値 | 183 |
| 最大 | 204 |
| 最小 | 169 |
| 分散 | 122 |
検証3よりも平均60ミリ秒程度優秀な結果が出ました。 毎回Workerの割り当てが走るという考察が間違っていたのか、メモリ割り当てを増やしたことによる初期化処理の高速化がWorker割り当てのオーバーヘッドを上回っているのか。。。分散が大きく減少したことを考えると、毎回Workerの割り当てが発生して、各Lambda関数間での数値のブレが小さくなったと解釈することもできそうです。
追加で分析・考察
検証4の結果を受けて、もう少し追加で分析・考察してみます。
検証5.VPC Lambdaでメモリ割り当てを増やしていった場合
検証4の結果の解釈として、メモリ割り当てを増やしたことによる初期化処理の高速化が非VPC LambdaでのWorker割り当てのオーバーヘッドを上回った可能性が考えられます。メモリ割り当てを増やすことで初期化処理がどの程度高速化するのか、VPC Lambdaのメモリ割り当てを調節しながら再度計測してみます。 VPC Lambdaの場合、Workerの新規割り当て有無=ENIの作成処理の有無を所要時間から簡単に判断できるので、秒単位のオーバーヘッドが発生した結果を除外して、Workerを再利用できたパターンのみで集計を行います。
結果は以下のようになりました。
| 指標 | 128M | 256M | 376M | 512M | 640M | 768M | 896M | 1024M | 1152M | 1280M |
|---|---|---|---|---|---|---|---|---|---|---|
| 平均 | 239 | 193 | 186 | 213 | 185 | 215 | 180 | 189 | 194 | 192 |
| 中央値 | 250 | 182 | 191 | 213 | 186 | 211 | 178 | 198 | 202 | 198 |
| 最大 | 273 | 238 | 214 | 219 | 214 | 240 | 241 | 225 | 233 | 240 |
| 最小 | 194 | 149 | 152 | 208 | 147 | 187 | 141 | 148 | 158 | 166 |
| 分散 | 765 | 1,172 | 506 | 11 | 682 | 298 | 856 | 666 | 654 | 651 |
メモリ割り当て376Mの方がメモリ割り当て1024Mより成績が良い等、少し解釈が難しい部分がありますが誤差ということにしておきます。まあ1G以上はメモリ割り当てを増やしていっても初期化処理は高速化されなさそうです。つまりメモリ割り当て1GのLambda関数とメモリ割り当て3GのLambda関数を比較した場合、初期化処理のオーバーヘッドは同等と考えて良さそうです。
検証6.非VPC Lambda × メモリ1024Mの場合
検証5の結果から、メモリ割り当て1GのLambda関数とメモリ割り当て3GのLambda関数を比較すると、初期化処理のオーバーヘッドは同等と考察しました。 ということは、Workerの割り当てが頻繁に発生するメモリ割り当て3GのLambda関数よりもメモリ割り当て1GのLambda関数の方が平均値は高速化するのではないでしょうか?非VPC Lambdaにメモリ1024Mの割り当てで計測した結果がこちらです。
| NO | 所要時間(ミリ秒) |
|---|---|
| 1 | 191 |
| 2 | 194 |
| 3 | 173 |
| 4 | 179 |
| 5 | 167 |
| 6 | 176 |
| 7 | 161 |
| 8 | 173 |
| 9 | 194 |
| 10 | 188 |
| 平均 | 180 |
| 中央値 | 178 |
| 最大 | 194 |
| 最小 | 161 |
| 分散 | 136 |
メモリを3008M割り当てた検証4よりもわずかながら高速化しました。比較するとこんな感じです。
| 指標 | 1024M | 3008M |
|---|---|---|
| 平均 | 180 | 184 |
| 中央値 | 178 | 183 |
| 最大 | 194 | 204 |
| 最小 | 161 | 169 |
| 分散 | 136 | 122 |
数ミリ秒レベルの違いですが、平均値は高速化しており、分散が増加しています。
- メモリ割り当て1024Mの方がWorkerの割り当て発生回数が少ないため平均値は高速化
- メモリ割り当て3008Mの場合は毎回Workerの割り当てが発生するため、分散が小さい
と解釈できなくもない??まあ数ミリ秒ベルの違いですし、最小値・最大値に関して1024Mの方が成績が良くなっているので、考察が正しかったと結論付けるには根拠が弱そうです。結局Workerとサンドボックス環境の関連性、コールドスタートの動作に関する考察は少しモヤっとした状態ですが、今日のところはここまでにしたいと思います。
まとめ
Lambdaのコールドスタートについて考察してみました。Worker回りの考察が正しいのかは分かりませんが、VPC LambdaとENIの関係についてはドキュメントにも明記されており、VPC Lambdaに関して言えばLambda関数に割り当てるメモリサイズを減らすことで、狭義のコールドスタート発生率を下げることができると言えます。メモリ割り当てを増やすことで、ENI作成を伴わないコールドスタートの高速化とhandler内の処理の高速化は期待できますが、改善効果としてはミリ秒単位の改善効果です。
- メモリ割り当てを増やして、毎回ミリ秒単位の高速化をはかる
- メモリ割り当てを減らして、秒単位のオーバーヘッドが発生するENI作成処理の発生率を下げる
どちらを優先して考えるかはユースケース次第です。Lambdaの特性をしっかりと理解した上で最適な選択肢を取っていきたいですね。










